ApplyAdagradDA
tensorflow C++ API
tensorflow::ops::ApplyAdagradDA
Update ‘*var’ according to the proximal adagrad scheme.
Summary
Arguments:
- scope: A Scope object
- var: Should be from a Variable().
- gradient_accumulator: Should be from a Variable().
- gradient_squared_accumulator: Should be from a Variable().
- grad: The gradient.
- lr: Scaling factor. Must be a scalar.
- l1: L1 regularization. Must be a scalar.
- l2: L2 regularization. Must be a scalar.
- global_step: Training step number. Must be a scalar.
Optional attributes (seeAttrs):
- use_locking: If True, updating of the var and accum tensors will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention.
Returns:
Output: Same as “var”.
ApplyAdagradDA block
Source link : https://github.com/EXPNUNI/enuSpaceTensorflow/blob/master/enuSpaceTensorflow/tf_training.cpp
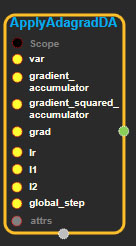
Argument:
- Scope scope : A Scope object (A scope is generated automatically each page. A scope is not connected.)
- Input var: connect Input node.
- Input gradient_accumulator: connect Input node.
- Input gradient_squared_accumulator: connect Input node.
- Input grad: connect Input node.
- Input lr: connect Input node.
- Input l1: connect Input node.
- Input l2: connect Input node.
- Input global_step: connect Input node.
- ApplyAdagradDA::Attrs attrs : Input attrs in value. ex) use_locking_ = false;
Return:
- Output output : Output object of ApplyAdagradDA class object.
Result:
- std::vector(Tensor) result_output : Returned object of executed result by calling session.
Using Method